FSDP 的起源
什么是数据并行?
在大模型出现之前,分布式训练最常用的技术是数据并行(Data Parallelism, DP)。
它的核心思想很简单:
- 每个 GPU 上都存放一份完整的模型副本
- 将一个大批次的数据(Global Batch)分成几个小批次(Micro-batches)
- 每个 GPU 只处理一个小批次的数据
- 当所有 GPU 完成前向和后向传播后,通过一次 AllReduce 通信操作同步所有梯度
- 确保所有 GPU 上的模型权重保持一致
这就像是多个人同时阅读同一本教科书,但每人只处理不同的习题,完成后大家交流答案,确保所有人都掌握了相同的知识。

数据并行的局限性
数据并行虽然简单高效,但它有一个致命的缺点:内存墙。
为什么会有内存墙?因为在传统数据并行中:
- 每个 GPU 必须存储完整的模型参数
- 每个 GPU 必须存储完整的梯度
- 每个 GPU 必须存储完整的优化器状态
当模型规模增长到数十亿甚至数千亿参数时,单个 GPU 的内存(通常为 16GB、32GB 或 80GB)根本无法容纳这些数据。
分片数据并行:打破内存墙的创新
分片数据并行(Sharded Data Parallelism) 提供了一个优雅的解决方案。它的核心思想是:消除冗余,按需加载。
具体做法是:
- 分片存储:将模型状态(参数、梯度、优化器状态)分割成多份,分配给不同的 GPU
- 按需聚合:计算时,通过 AllGather 通信操作临时重建完整参数
- 即用即弃:计算完成后立即释放聚合的参数,释放内存
这一突破性技术最初由微软的 ZeRO(Zero Redundancy Optimizer) 提出,并成为了 PyTorch FSDP(Fully Sharded Data Parallel)的理论基础。
光看上面的描述,初学者容易有的疑惑就是在 FSDP 加载的时候,也是把模型的完整参数都放到 GPU 里面进行计算。这样的话,它消耗的显存跟 DP 有什么区别吗?
这是一个好问题,表面上看,FSDP 在计算时确实会把完整参数加载到 GPU 中,那它为什么能节省显存呢?关键在于时间差和计算粒度。
想象一下这个场景:
- 传统数据并行 (DP):就像是一次性把整本百科全书都放在你的桌子上。无论你当前查阅哪一页,整本书都占据着你的桌面空间。
- 分片数据并行 (FSDP):就像是把百科全书分成多卷,分别放在不同的书架上。你只在需要查阅某一章节时,才临时把相关的几页放到桌面上,查完立即归还书架,为下一章节腾出空间。
具体来说,FSDP 的显存优势体现在:
- 分层计算:FSDP 不是一次性加载整个模型,而是按照模型的层或模块逐个计算。计算完一个模块后,立即释放其完整参数,只保留该模块的分片。
- 即用即弃:在计算某层时,确实会通过 AllGather 操作重建完整参数,但计算完成后立即释放这些临时聚合的参数。
- 峰值显存降低:虽然在某一时刻可能需要完整参数,但由于是分层计算,任何时刻内存中只有当前正在计算的那一层的完整参数,而不是整个模型的完整参数。
- 优化器状态始终分片:优化器状态(如 Adam 的动量)通常比模型参数本身占用更多内存,在 FSDP 中这部分始终保持分片状态,从不合并。
简单来说,DP 是”全时全量”,而 FSDP 是”分时分量”。这种精细化的内存管理策略使得 FSDP 能够训练比 DP 大得多的模型。
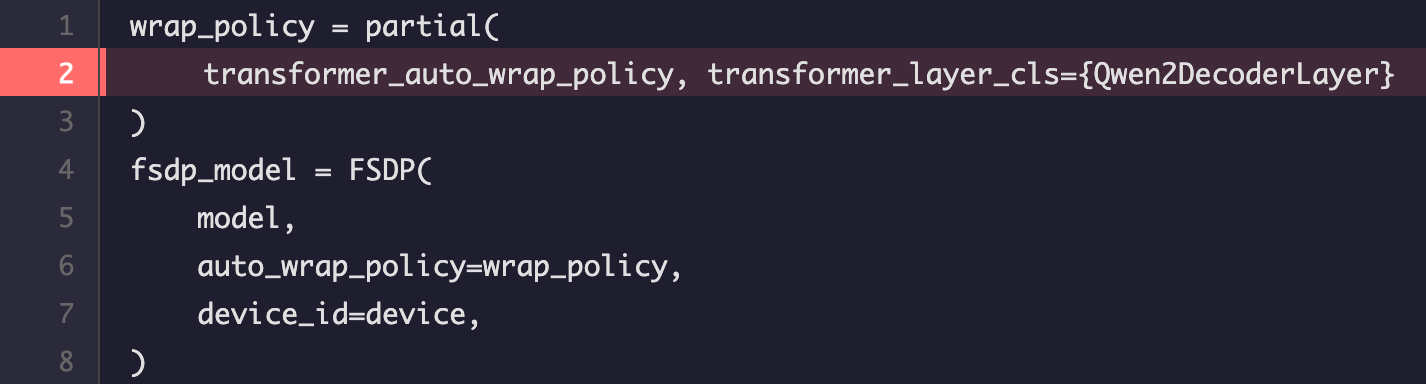
在训练 Transformer 模型的时候,一般都是把一层的 Transformer 作为一个 FSDP 计算单元。比如对 Qwen2.5-7B 的模型进行 FSDP 训练的时候,我们一般指定
transformer_layer_cls={Qwen2DecoderLayer} ,这样 FSDP 就会默认只对Qwen2DecoderLayer 进行分片。
下面是我打印的 fsdp_model 的模型结构,可以发现只有 Qwen2DecoderLayer 被套上 FullyShardedDataParallel
FullyShardedDataParallel(
(_fsdp_wrapped_module): Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584)
(layers): ModuleList(
(0-27): 28 x FullyShardedDataParallel(
(_fsdp_wrapped_module): Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
)FSDP 的实例
假设我们现在在 4 卡上面运行 FSDP,每个 GPU 会分到对应的数据分片,每个 GPU 现在分到了一个 FSDP 计算单元(比如一个 Transformer 块)的四分之一参数。如下图所示:

FSDP 的高效内存管理机制体现在其计算生命周期的四个关键阶段。每个被 FSDP 包装的模块(称为 FSDP 单元)在前向和后向传播过程中都遵循以下固定流程:
前向传播前
- 执行 all_gather 通信操作
- 从所有 GPU 收集当前单元的参数分片
- 在每个 GPU 上重构完整参数
- 此时每个 GPU 临时获得完整权重

前向传播
- 使用重构的完整参数进行计算
- 每个 GPU 处理自己分配到的数据批次
- 执行标准的本地前向计算过程

前向传播后
- 立即释放通过 all_gather 获得的完整参数
- 每个 GPU 只保留自己负责的参数分片
- 这个”重新分片”(Resharding)过程是节省内存的关键
- 确保 GPU 内存中只保留当前计算单元的完整参数

后向传播
- 与前向传播类似但方向相反
- 再次通过 all_gather 重构完整参数
- 使用完整参数计算梯度

后向传播后
- FSDP 使用 reduce_scatter 操作而非 DDP(DistributedDataParallel 即传统的数据并行)的 all_reduce
- reduce_scatter 在一步内完成梯度求和并分发回各 GPU
- 每个 GPU 只接收自己负责部分的梯度分片
- 使用本地梯度分片和优化器状态分片更新参数

这种精确控制参数加载和释放的机制,使 FSDP 能够训练远超单个 GPU 内存容量的大型模型。
FSDP 实践
前面我们从理论上面分析 FSDP 的原理,为了加深理解,下面我会以 Qwen2.5-7B 为例,对比单卡和两卡运行 FSDP 的效果,注意为了演示方便,我只截取最前面的一个 Transformer layer 的计算过程。
单卡的运行结果
| t_ms | phase | layer | alloc_MB | reserved_MB |
|---|---|---|---|---|
| 2158.008 | FSDP_forward_pre | root | 14526.63134765625 | 17112.0 |
| 2331.595 | FSDP_forward_pre | 0 | 14558.7783203125 | 17112.0 |
| 2332.574 | BLOCK_forward_pre | 0 | 14558.7783203125 | 17112.0 |
| 2443.74 | BLOCK_forward_post | 0 | 14563.62646484375 | 17116.0 |
| 2444.327 | FSDP_forward_post | 0 | 14563.62646484375 | 17116.0 |
两卡运行结果
| t_ms | phase | layer | alloc_MB | reserved_MB |
|---|---|---|---|---|
| 4589.679 | FSDP_forward_pre | root | 7263.31689453125 | 12382.0 |
| 4968.469 | FSDP_forward_pre | 0 | 9375.4638671875 | 14462.0 |
| 4982.273 | BLOCK_forward_pre | 0 | 9819.986328125 | 14908.0 |
| 5111.311 | BLOCK_forward_post | 0 | 9824.83447265625 | 14912.0 |
| 5112.06 | FSDP_forward_post | 0 | 9380.31201171875 | 14912.0 |
表格记录了 FSDP 训练过程中的关键指标,各列含义如下:
-
t_ms:时间戳(毫秒),记录操作发生的时间点
-
phase:当前执行阶段
-
FSDP_forward_pre:前向传播前的准备阶段,执行 all_gather 操作 -
BLOCK_forward_pre:模型块前向计算前 -
BLOCK_forward_post:模型块前向计算后 -
FSDP_forward_post:前向传播后的清理阶段,执行重新分片操作 -
layer:当前操作涉及的模型层索引,0 表示第一层
-
alloc_MB:已分配的 GPU 内存,单位为 MB
-
reserved_MB:CUDA 为模型预留的 GPU 内存,通常大于实际分配量
从数据对比可以清晰看出 FSDP 的内存优势:
- 单卡:内存占用约 14.5GB,预留 17.1GB
- 两卡:每卡内存占用约 9.8GB,预留 12.3-14.9GB
接下来我们深入分析两卡 FSDP 各个阶段的显存变化:
第一阶段:前向传播准备(FSDP_forward_pre) 内存占用:约 9375 MB
这是计算开始前的状态。此时,GPU 只保存了该层的参数分片和必要的激活值。这是 FSDP 的基本原则:只在需要时聚合参数,用完立即释放。
第二阶段:模型层计算前(BLOCK_forward_pre) 内存变化:
- 已分配内存从 9375 MB 增加到 9820 MB
- 预留内存从 14462 MB 增加到 14908 MB
此阶段发生了两个关键操作:
- 参数聚合:FSDP 通过 all-gather 通信操作,从各个 GPU 收集参数分片,在每个 GPU 上重建完整的参数。
- 内存分配:系统向 CUDA 缓存分配器申请显存块,用于存储完整参数和计算工作区。如果缓存中没有合适大小的块,就会向 CUDA 请求新的内存段。
第三阶段:模型层计算后(BLOCK_forward_post) 内存变化:从 9820 MB 微增至 9825 MB
前向计算完成后,系统需要保留一部分中间结果(激活值)供反向传播使用。这些中间结果主要包括 MLP 和注意力机制的输出。同时,一些临时工作区被释放,导致内存占用略有变化。
第四阶段:前向传播完成(FSDP_forward_post) 内存变化:
- 已分配内存显著下降至 9381 MB
- 预留内存保持不变(14912 MB)
这是 FSDP 内存效率的关键阶段。由于默认启用了reshard_after_forward=True选项,系统会:
- 立即释放通过 all-gather 获得的完整参数
- 将参数恢复为分片状态
- 只保留必要的激活值
释放的内存不会立即返回给 CUDA(因此预留内存不变),而是标记为”空闲块”,可供后续操作复用。
这种”即用即释放”的策略使 FSDP 能够训练远超单个 GPU 内存容量的大型模型。
为什么 2 卡 FSDP 的单卡显存占用不是单卡训练的一半?
如果你仔细观察,会发现一个问题:单卡训练占用 14 GB,用 FSDP 2 卡分片按理说应该是每张卡占用 7GB,怎么会是 9GB 呢?多出来的 2 GB 是什么?
这种差异主要由两个因素导致:
1. 非分片参数的存在
某些模型组件在当前的 auto-wrap 配置下没有被单独包装为 FSDP 单元,因此不会被分片:
-
词嵌入层(
embed_tokens)和输出层(lm_head)会在 FSDP 中以完整参数参与前向计算 -
这些组件通常占用大量显存,例如 Qwen2.5-7B 模型中:
-
词嵌入层:152064×3584×2 字节 ≈ 1.02 GiB
-
输出层:额外 ≈ 1.02 GiB
-
合计约 2.04 GiB,与实测增加的 2.11 GiB 非常接近
2. 临时全权重缓冲
在计算每个 Transformer 块前,FSDP 需要通过 all-gather 操作临时重建完整参数:
- 每个 block 前向计算前会分配额外显存用于存储该 block 的完整权重
- 对于 Qwen2.5-7B,单层全权重缓冲约占 0.44 GB
实际显存变化分析
通过分析两卡 FSDP 训练的显存变化,我们可以清晰看到这些因素的影响:
-
初始基线:7.26 GB(确实约为单卡 14.53 GB 的一半,参数分片生效)
-
第一次显存增加:+2.11 GB(7.26 → 9.38 GB)
-
发生在进入第 0 层前
-
主要是词嵌入和输出层全量聚合导致
-
第二次显存增加:+0.44 GB(9.38 → 9.82 GB)
-
发生在第 0 层计算前
-
是第 0 层权重的 all-gather 缓冲
-
计算后显存回落:9.82 → 9.38 GB
-
因为启用了
reshard_after_forward=True -
该层的全权重缓冲被释放回缓存,只保留激活值
这解释了为什么 2 卡 FSDP 训练时,单卡显存占用约为 9GB,而不是单纯的 7GB。
前向重叠与后向重叠
FSDP 的提出是为了解决单个模型无法放到一个 GPU 上面进行训练的难题,它的核心思想是通过切分模型的状态来解决显存不足的问题,它的代价是每次计算都需要进行通信,但是通过前向重叠和后向重叠,可以把这部分通信时间消除掉。
我们先来看不重叠的情况:

如果不重叠的话,AG 跟 FWD 是串行执行,那 AG 的通信耗时就会增加整体的训练耗时。RS 和 BWD 同理。此时 Forward 整体耗时 240 ms,Backward 整体耗时 320 ms。
好在计算和通信是可以重叠的,打开重叠是下面的效果:

前向重叠开启,AG1 可以在 FWD0 的时候并行加载,此时 Forward 整体耗时 180 ms,减少了 60 ms。
后向重叠开启,Backward 整体耗时 210 ms。不仅跨层的 RS 和 BWD 可以重叠执行,同层的 RS 跟 BWD 也可以部分重叠执行。因为在反向传播这件事上,FSDP 有个很妙的优化,它不会等所有梯度都计算好再一股脑儿地去同步,而是把梯度打包成一个个的“桶”。一旦某个桶满了,就立刻把它发走进行规约(一种多 GPU 的数据同步操作),完全不用等其他的计算。
这里的“桶”有多大(也就是 bucket_cap_mb)就成了一个权衡点。
如果桶很小,那它很快就会被装满,通信能更早开始,从而和后续的计算过程更好地重叠。但代价是,通信会更频繁。
如果桶很大,你就能减少通信的总次数,但需要等更久才能装满一个桶,这又可能导致计算在等待通信,重叠效果就差了。
PyTorch 默认的大小是 25MB,这通常是一个不错的平衡点,既能实现重叠,又不至于让通信过于碎片化。
总结
在分布式训练中,为了解决单卡显存不足和计算效率的问题,有两条主要的技术路线:一条是以 FSDP 为代表,通过切分模型的状态来解决内存问题;另一条则是以 Megatron-LM 为代表,通过切分模型的计算来解决内存问题。
NVIDIA 的 Megatron 就像一个硬件大师,它的方法是切分“计算”本身。它把模型运算(张量并行、流水线并行)拆解得明明白白,追求极致的计算效率。
而微软的 ZeRO(也就是 FSDP 的前身)则像一个内存管理专家,它的方法是切分“数据”。它把模型参数、梯度、优化器状态这些东西都打散了,只在需要用的那一刻才把它们聚合起来,用完就扔,以此来节省空间。
后来,大家都发现对方的路子也有可取之处。于是 FSDP 开始学习如何做张量并行,而 Megatron 也学会了分散优化器状态。最终,现实世界里最有效的方案,就是把两家的长处结合起来:用 Megatron 的思路切分计算,用 ZeRO 的思路切分数据。这其实很常见,当两个聪明的团队从不同角度解决同一个难题时,最终的答案往往是两者的结合。
下一篇文章我会带大家进入 Megatron 的世界,这也是现在大型 MoE 模型训练必备训练框架。