最简单的 KV 数据库需要多少行代码实现?答案是不到 50 行。接下来我会带你实现一个基于日志顺序写入的数据库,它的功能很简单,支持写入和查询字符串类型的 key 和 value。
一个 KV 数据库最重要的是存储实现,因为它的查询语法很简单,根据 key 查询 value 就行,不像关系型数据库还需要实现解析器和优化器来解析 SQL 语法以及执行计划优化。那么我们这个简单的 KV 数据库的存储实现是怎样的呢?它的存储格式是一个纯文本文件,就像我们常用的日志文件一样,每一行是一个 JSON 格式的 key-value 对。每次写入一对 key-value 就是在日志文件里面新加一行到文件的末尾,因此多次写入同一个 key,旧版本的值不会被覆盖,当需要查询一个 key 的最新 value 时,需要从头找到尾,最后一个 key 对应的 value 就是这个 key 最新的值。
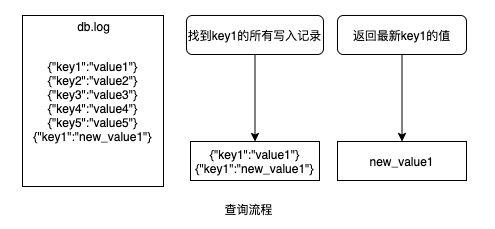
举个例子,下图中 key1 写入了两条记录,当我们查询的时候,先找到 key1 的两条记录,然后返回最新的那条记录中的 value。因为这种存储方式很像我们平时写日志的方式:顺序写入,不做更新,所以我们一般把这个存储的文件也叫做日志。
代码实现
接下来,我们一起来动手实现这个简单的日志数据库,本节的代码实现可以到 GitHub 上面下载:https://github.com/x-hansong/miniDb/tree/pure_log
首先,定义出我们的数据库接口,接口很简单,一个 put 接口,入参字符串类型的 key 和 value,一个 get 接口入参是字符串类型的 key,出参是字符串类型的 value。
/**
* 数据库接口
*/
public interface MiniDb {
void put(String key, String value);
String get(String key);
}然后实现 MiniDb 的接口,参考 PureLogDb 的这个类,其中类的构造方法入参是 logPath,就是日志文件的路径,在构造方法中我们通过 new File(logPath) 实例化了一个文件对象 logFile,用于后续的读写。
public class PureLogDb implements MiniDb {
private File logFile;
public PureLogDb(String logPath) {
logFile = new File(logPath);
}
.....
}先实现第一个 put 接口,支持把 key-value 写入到日志文件里面。
@Override
public void put(String key, String value) {
try {
FileWriter fileWriter = new FileWriter(logFile, true);//1
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);//2
JSONObject kv = new JSONObject();//3
kv.put(key, value);
bufferedWriter.write(kv.toJSONString());//4
bufferedWriter.newLine();//5
bufferedWriter.close();//6
} catch (Throwable t) {
throw new RuntimeException(t);
}
}-
实例化一个文件写入器,第一个参数 logFile 是指要写入的文件对象,第二个参数 true 是表示写入的时候用追加的方式写入,默认情况下 fileWriter 每次写入都是先清空文件已有内容,然后再写入。清空的方式这样不符合我们的预期,所以我们要指定为按照追加的方式写入文件。
-
实例化一个缓存写入器,BufferedWriter 提供了一种方便的字符流写入文件的方式。
-
实例化一个 JSON 对象 kv,把我们的 key 和 value 放到 kv 中。
-
通过 bufferedWriter 把 kv 按照 JSON 字符串的格式写入到文件里面。
-
让 bufferedWriter 插入一个换行符,这样方便我们读取的时候按行读取。
-
关闭 bufferedWriter 的文件流。
在实现完 put 接口之后,我们再来实现 get 接口,把 put 写入的数据读取出来。
@Override
public String get(String key) {
try {
FileReader fileReader = new FileReader(logFile);//1
BufferedReader bufferedReader = new BufferedReader(fileReader);//2
String line = bufferedReader.readLine();//3
LinkedList<String> values = new LinkedList<>();//4
while (line != null) {//5
JSONObject kv = JSONObject.parseObject(line);//6
if (kv.getString(key) != null) {//7
values.add(kv.getString(key));
}
line = bufferedReader.readLine();//8
}
if (values.size() != 0) {//9
return values.getLast();
}
} catch (Throwable t) {
throw new RuntimeException(t);
}
return null;//10
}-
实例化一个文件读取器 fileReader。
-
实例化一个缓存读取器 bufferedReader,它提供了按行读取数据的接口,方便我们读取数据。
-
从日志文件中读取一行,假设前面 put 写入了:{“key1”:“value1”},那么这里读取出来的就是:{“key1”:“value1”}。
-
构造一个链表数组,用来存放从日志文件中读取出来的多条 key 的数据记录,前面我们提到了日志文件是顺序追加写入的,不会覆盖已有的数据,所以同一个 key 可能会有多条数据。
-
判断读取的 line 是不是为 null,为 null 说明已经读取到文件尾部,没有数据了。如果不为 null 就进入循环。
-
把读取出来的数据转化为 JSON 对象 kv。
-
从 kv 中读取 key 看看能不能读取到数据,为 null 说明这个 kv 不是我们想要的,不为 null 说明 kv 就是我们读取到的数据。
-
while 循环的结尾重新从文件中读取一行数据。
-
遍历完文件之后,判断一下有没有从文件中读取到 key 对应的数据记录,如果 values.size() == 0 说明文件中没有 key 对应的数据。如果有 size ≠0,那就把最后的数据记录返回。因为数据是顺序写入的,所以最后一条数据是最新写入的,这样才能保证读取的数据是最新,通过这种方式我们可以实现不覆盖更新也能读取到最新的数据。这是日志型数据库非常重要的思路。
-
最后如果没有找到数据,就返回 null。
最后我们来测试一下这个迷你的日志数据库,相关的代码是 com.xiaohansong.minidb.purelog.PureLogDbTest。
public class PureLogDbTest {
@Test
public void test() {
PureLogDb pureLogDb = new PureLogDb("db.log");//1
for (int i = 0; i < 10; i++) {//2
pureLogDb.put("key" + i, "value" + i);
}
for (int i = 0; i < 10; i++) {//3
Assert.assertEquals("value" + i, pureLogDb.get("key" + i));
}
for (int i = 0; i < 10; i++) {//4
pureLogDb.put("key" + i, "new_value" + i);
}
for (int i = 0; i < 10; i++) {//5
Assert.assertEquals("new_value" + i, pureLogDb.get("key" + i));
}
for (int i = 10; i < 20; i++) {//6
assertNull(pureLogDb.get("key" + i));
}
}
}-
实例化一个数据库对象 pureLogDb,日志文件名是 db.log。
-
测试写入:从 0 到 9 写入数据,即{“key0”:“value0”}到{“key9”:“value9”}。
-
测试读取:从 0 到 9 读取数据,即从 key0 读取到 key9,判断返回的值是不是跟写入的值一样。
-
测试覆盖写入,把原来的 key0 到 key9 的值写入为 new_value*。
-
测试读取新的 value 值:即从 key0 读取到 key9,判断返回的值是不是 new_value*。
-
测试读取不存在的值:读取 key10 到 key19,因为前面没有写入,所以读取出来的一定都是 null。
实现删除功能
到目前为止,我们成功的实现了一个简单的日志型 KV 数据库,支持 put 和 get 操作,但是有一个问题是删除操作不支持,因为数据存储采用的是追加式写入,已经写入的数据就没法删除掉了,怎么办呢?其实我们可以换个思路,把 remove 也当做是一次 put,只不过 remove 写入不是 key-value,而是写入对 key 的删除记录。这个方式就要求我们存储到日志里面的数据不再是原始的 key-value,而是记录数据的操作。
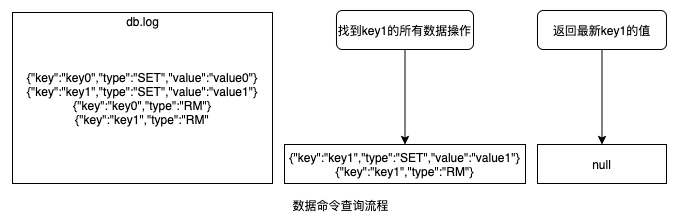
举个例子,如下图所示,日志文件中存储的不再是 key-value,而是数据命令,包括 SET 命令和 RM 命令。SET 命令是赋值的意思,也就是对 key 赋值 value。RM 命令是删除 key 的意思。当我们要查询 key1 的值时,先从日志文件中查询出 key1 的所有数据命令,然后找到最新的一条命令,如果是 SET 命令就返回 SET 命令的 value 值;如果是 RM 命令就返回 null,因为此时在数据库中 key1 的状态是被删除。
接下来我们修改 PureLogDb 的代码,来实现删除的功能。完整的代码参考:https://github.com/x-hansong/miniDb/tree/pure_log_with_rm
首先要定义出数据命令的接口,因为 SET 命令和 RM 命令的共同属性是 key,所以定义了 getKey 方法。
public interface Command {
/**
* 获取数据key
* @return
*/
String getKey();
}然后定义一个命令类型的枚举,分别是 SET 和 RM,代表两种操作。
public enum CommandTypeEnum {
/**
* 保存命令
*/
SET,
/**
* 删除命令
*/
RM
}因为 SET 和 RM 命令都有命令类型字段,而且都需要序列化成 JSON 的方法,所以我们可以实现一个抽象类 AbstractCommand,把公共的方法和字段放到抽象类中。
public abstract class AbstractCommand implements Command {
/**
* 命令类型
*/
private CommandTypeEnum type;
public AbstractCommand(CommandTypeEnum type) {
this.type = type;
}
@Override
public String toString() {
return JSON.toJSONString(this);
}
...
}有了抽象类之后,我们就可以分别实现 SetCommand 和 RmCommand 了。在构造方法中 SetCommand 和 RmCommand 分别赋值了各自的命令类型,SetCommand 主要比 RmCommand 多一个 value 字段。
public class SetCommand extends AbstractCommand {
/**
* 数据key
*/
private String key;
/**
* 数据值
*/
private String value;
public SetCommand(String key, String value) {
super(CommandTypeEnum.SET);
this.key = key;
this.value = value;
}
...
}
public class RmCommand extends AbstractCommand {
/**
* 数据key
*/
private String key;
public RmCommand(String key) {
super(CommandTypeEnum.RM);
this.key = key;
}
...
}在加入了数据命令之后,对于之前的读写流程有什么影响?下面我们来看一下经过修改之后的 put 和 get 方法。
首先是 put 方法,主要改变就是原来直接写入 key-value 的代码改成写入 SetCommand。
public void put(String key, String value) {
try {
FileWriter fileWriter = new FileWriter(logFile, true);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
SetCommand setCommand = new SetCommand(key, value);//改动的代码
bufferedWriter.write(setCommand.toString());
bufferedWriter.newLine();
bufferedWriter.close();
} catch (Throwable t) {
throw new RuntimeException(t);
}
}然后是 get 方法
public String get(String key) {
try {
FileReader fileReader = new FileReader(logFile);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line = bufferedReader.readLine();
LinkedList<Command> commands = new LinkedList<>();
while (line != null) {
JSONObject command = JSONObject.parseObject(line);
if (key.equals(command.getString(KEY))) {
if (CommandTypeEnum.SET.name().equals(command.getString(TYPE))) {//1
commands.add(command.toJavaObject(SetCommand.class));
} else if (CommandTypeEnum.RM.name().equals(command.getString(TYPE))) {
commands.add(command.toJavaObject(RmCommand.class));
}
}
line = bufferedReader.readLine();
}
if (commands.size() != 0) {
if (commands.getLast() instanceof SetCommand) {//2
return ((SetCommand) commands.getLast()).getValue();
} else if (commands.getLast() instanceof RmCommand) {
return null;
}
}
} catch (Throwable t) {
throw new RuntimeException(t);
}
return null;
}-
在读取了数据命令之后,要判断一下命令的类型,对 SET 和 RM 命令分别进行反序列化。
-
获取 key 的最新命令,如果是 SetCommand 类型就返回 SetCommand 的 value 值,如果是 RmCommand 就直接返回 null。
至于 remove 方法,其实跟 put 方法类似,就是写入一条数据命令,不同的是 remove 方法写入的 RmCommand。
public void remove(String key) {
try {
FileWriter fileWriter = new FileWriter(logFile, true);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
RmCommand rmCommand = new RmCommand(key);//这里写入的是删除命令
bufferedWriter.write(rmCommand.toString());
bufferedWriter.newLine();
bufferedWriter.close();
} catch (Throwable t) {
throw new RuntimeException(t);
}
}小结
至此,我们通过不到 50 行代码就实现了一个简单的日志型 KV 数据库,接下来我们分析一下它的优缺点。
KV 数据库非常重要的性能指标有两个,分别是写入性能和读取性能。在写入上面,PureLogDb 采用顺序追加写入的方式,这种写入方式无论是在磁盘还是 SSD 上面,性能都是最高的,可以说跟市面上的数据库例如 Hbase、MySQL 都可以一较高下,因为 Hbase 也是采用了顺序写入的方式,而 MySQL 则是覆盖更新的写入,写入性能还不如 PureLogDb。但是在读取性能上面,PureLogDb 则性能非常差,当日志文件里面保存了大量数据的时候,每次要查询一个 key,都要从头扫到尾来找到 key 的所有数据记录。查询的算法复杂度是 O(n),也就是说如果数据库的数据翻倍,那么查询耗时同样也要翻倍。此外 PureLogDb 这种追加写入的方式也不支持删除操作。