原理简介
在之前的文章《ChatGLM3 的工具调用(FunctionCalling)实现原理》里面,我们介绍了 ChatGLM3 工具调用的原理,其本质就是让大模型通过微调学会根据 prompt 中的函数的定义学会下一步应该调用哪个函数,然后我们解析大模型预测的文本结果去执行对应的函数,最后再把执行的结果拼接到 prompt 中,让大模型继续预测后续的步骤。
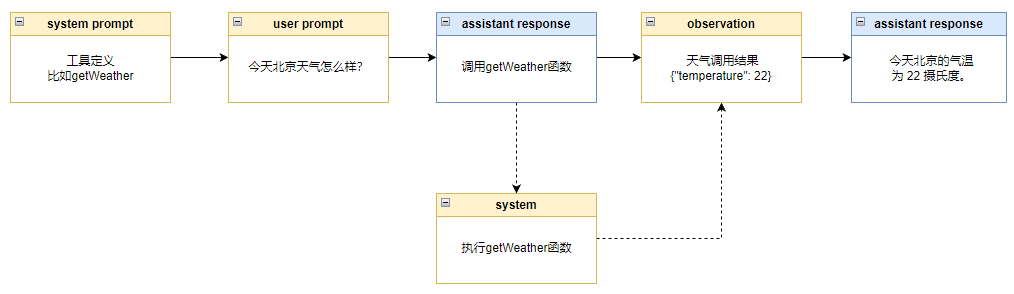
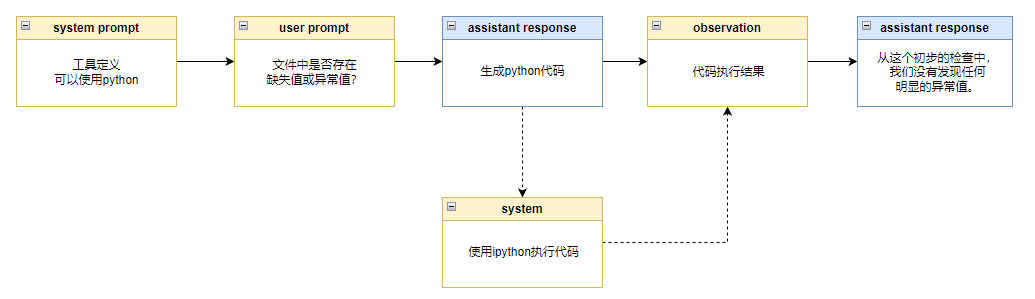
大家之前看 GPT4 的代码解释器功能很厉害,可以读取 excel 做数据分析,看起来很神奇。但是它背后的原理其实跟工具调用是一样的。无非就是将普通的函数替换成代码解释器,大模型预测的结果不再是函数的入参,而是具体的代码,根据这些代码我们调用代码解释器执行,然后在界面上面支持显示代码执行的结果。从这个角度看,代码解释器本质上是大模型工具调用能力的一种特例。
训练样本
要了解大模型是如何学会使用代码解释器的,就要先看训练样本是如何构造的。下面是一个官方提供的例子:
<|system|>
你是一位智能AI助手,你叫ChatGLM3,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
<|user|>
帮我画一个爱心
<|assistant|>interpreter
```python
import numpy as np
import matplotlib.pyplot as plt
# 爱心形状的参数方程
def heart(t):
x = 16 * np.sin(t) ** 3
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
return x, y
t = np.linspace(0, 2 * np.pi, 1000)
x, y = heart(t)
plt.figure(figsize=(6, 6))
plt.plot(x, y, color='red')
plt.axis('equal')
plt.axis('off')
plt.show()
```
<|observation|>
```result
【image】
```
<|assistant|>
这是一个爱心形状。我使用了参数方程来描述这个形状,并使用matplotlib进行了绘制。如果您有任何其他需求或问题,请随时告诉我。
<|user|> # End可以看到,训练样本中首先是定义了 system prompt,引导大模型使用 Python。同时还告诉大模型文件存放的位置,这样大模型在预测代码的时候就能够知道去哪里读取文件。
<|system|>
你是一位智能 AI 助手,你叫 ChatGLM3,你连接着一台电脑,但请注意不能联网。在使用 Python 解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。然后在用户的问题之后就跟着具体的 python 代码,用 interpreter 作为开头。
<|assistant|>interpreter
```python
import numpy as np
import matplotlib.pyplot as plt
# 爱心形状的参数方程
def heart(t):
x = 16 * np.sin(t) ** 3
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
return x, y
t = np.linspace(0, 2 * np.pi, 1000)
x, y = heart(t)
plt.figure(figsize=(6, 6))
plt.plot(x, y, color='red')
plt.axis('equal')
plt.axis('off')
plt.show()
```最后是代码执行的结果,由于图片没法转成文字,所以用【image】表示。
<|observation|>
```result
【image】
```通过大量的样本,大模型学会使用 python 执行代码,接下来就是如何在推理的时候执行代码。
代码解释器执行源码分析
下面的代码来自官方提供的例子:
ChatGLM3/composite_demo/demo_ci.py at main · THUDM/ChatGLM3 · GitHub
首先看 main 方法做了什么
def main(top_p: float, temperature: float, prompt_text: str):
...
if prompt_text:
for _ in range(5):
output_text = ''
for response in client.generate_stream():
token = response.token
if response.token.special:
match token.text.strip():
case '<|user|>':
append_conversation(Conversation(
Role.ASSISTANT,
postprocess_text(output_text),
), history, markdown_placeholder)
return
# Initiate tool call
case '<|assistant|>':
append_conversation(Conversation(
Role.ASSISTANT,
postprocess_text(output_text),
), history, markdown_placeholder)
message_placeholder = placeholder.chat_message(name="interpreter", avatar="assistant")
markdown_placeholder = message_placeholder.empty()
output_text = ''
continue
case '<|observation|>':
code = extract_code(output_text)
print("Code:", code)
display_text = output_text.split('interpreter')[-1].strip()
append_conversation(Conversation(
Role.INTERPRETER,
postprocess_text(display_text),
), history, markdown_placeholder)
message_placeholder = placeholder.chat_message(name="observation", avatar="user")
markdown_placeholder = message_placeholder.empty()
output_text = ''
with markdown_placeholder:
with st.spinner('Executing code...'):
try:
res_type, res = execute(code, get_kernel())
except Exception as e:
st.error(f'Error when executing code: {e}')
return
print("Received:", res_type, res)
if res_type == 'text' and len(res) > TRUNCATE_LENGTH:
res = res[:TRUNCATE_LENGTH] + ' [TRUNCATED]'
append_conversation(Conversation(
Role.OBSERVATION,
'[Image]' if res_type == 'image' else postprocess_text(res),
tool=None,
image=res if res_type == 'image' else None,
), history, markdown_placeholder)
message_placeholder = placeholder.chat_message(name="assistant", avatar="assistant")
markdown_placeholder = message_placeholder.empty()
output_text = ''
break
case _:
st.error(f'Unexpected special token: {token.text.strip()}')
break上面的代码我做了简化,主要关注对话处理的核心流程:代码段使用 Python 中的match语句,类似于传统的switch-case结构。各个分支根据token.text.strip()的值执行不同的操作:
- 第一个
case '<|user|>':当输出的token文本为空时,将之前的output_text作为助理的回答加入历史记录。并结束当前的对话流程。 - 第二个
case '<|assistant|>':同样是当输出的token文本为空时。将之前的output_text作为助理的回答加入历史记录。接下来,创建一个新的消息占位符,准备执行工具调用。 - 第三个
case '<|observation|>':提取output_text中的代码部分。从output_text中提取出最后一个interpreter之后的文本。将提取出的文本作为interpreter的回复加入历史记录。创建一个新的消息占位符,准备显示执行代码的结果。res_type, res = execute(code, get_kernel())执行提取的代码,捕获任何异常,并将结果显示在屏幕上。 - 第四个
case _:这是一个默认的分支,处理未预期的特殊令牌。如果令牌不符合以上的任何情况,则会显示一个错误消息。
代码的逻辑比较简单,类似我们之前讲过的工具调用的过程。至于代码执行使用的jupyter_client这个包,感兴趣的可以自己研究一下。